










Жизнь 3.0. Как быть человеком в эпоху искусственного интеллекта
20-03-2019
Max Erik Tegmark[1] (born Max Shapiro[2][3] on 5 May 1967) is a Swedish-American physicist and cosmologist. He is a professor at the Massachusetts Institute of Technology and the scientific director of the Foundational Questions Institute. He is also a co-founder of the Future of Life Institute and a supporter of the effective altruism movement, and has received donations from Elon Musk to investigate existential risk from advanced artificial intelligence.Глава из недавно вышедшей книги Life 3.0: Being Human in the Age of Artificial Intelligence (с незначительными сокращениями)
Цифро‑утописты
Ребенком я был уверен, что все миллиардеры просто сочатся помпезностью и невежеством. Когда в 2008 году в Google я впервые встретил Ларри Пейджа, он напрочь разрушил оба этих стереотипа. Впечатление подчеркнутой небрежности в одежде создавалось джинсами и ничем не примечательной майкой, словно он собрался на университетский пикник. Задумчивая манера говорить и мягкий голос, скорее, успокоили и расслабили меня, чем напугали и напрягли. 18 июля 2015 года мы снова увиделись в Напа‑Вэлли на вечеринке, устроенной Илоном Маском и его тогдашней женой Талулах, и между нами немедленно завязался разговор о копрологических интересах наших детей. Я порекомендовал ему литературную классику Энди Гриффитса – The Day My Butt Went Psycho, которую он тут же себе заказал. Мне пришлось напомнить себе, что этот человек, вероятно, войдет в историю как оказавший на нее наибольшее влияние: если, как я думаю, сверхчеловеческому искусственному интеллекту суждено просочиться во все уголки нашей Вселенной еще при моей жизни, то это может случиться исключительно благодаря решениям Ларри.
С нашими женами, Люси и Мейей, мы отправились ужинать, и во время еды мы обсуждали, непременно ли машины будут обладать сознанием – идея, как он утверждал, совершенно ложная и пустая. А уже ночью, после коктейля, у них с Илоном разразился длинный и бурный спор о будущем искусственно интеллекта. Уже близился рассвет, а толпа любопытных зевак вокруг них продолжала расти. Ларри яростно защищал позицию, которую я бы отождествил с цифро‑утопистами: он говорил, что цифровая жизнь – естественный и желательный новый этап космической эволюции, и если мы дадим ей свободу, не пытаясь удушить или поработить ее, то это принесет безусловную пользу всем. На мой взгляд, Ларри самый яркий и последовательный выразитель идей цифро‑утопизма. Он утверждал, что если жизни суждено распространиться по всей Вселенной, в чем сам он был убежден, то произойти это может только в цифровом виде. Самую большую тревогу у него вызывала опасность, что AI‑паранойя способна затормозить наступление цифровой утопии и даже спровоцировать попытку силой овладеть искусственным интеллектом в нарушение главного лозунга Google “Не твори зла!”. Илон старался вернуть Ларри на землю и без конца спрашивал его, откуда такая уверенность, что цифровая жизнь не уничтожит вокруг все то, что нам дорого. Ларри то и дело принимался обвинять Илона в “видошовинизме” – стремлении приписать более низкий статус одним формам жизни в сравнении с другими на том простом основании, что главный химический элемент в их молекулах кремний, а не углерод.
Хотя в тот вечер у бассейна Ларри оказался в меньшинстве, у цифровой утопии, в защиту которой он так красноречиво выступал, немало выдающихся сторонников. Робототехник и футуролог Ганс Моравец[1] своей книгой Mind Children 1988 года, ставшей классикой жанра, воодушевил целое поколение цифро‑утопистов. Его дело было подхвачено и поднято на новую высоту Рэем Курцвейлом. Ричард Саттон, один из пионеров такой важной AI‑отрасли, как машинное обучение, выступил со страстным манифестом цифро‑утопистов на нашей конференции в Пуэрто‑Рико.
Техноскептики
Следующая группа мыслителей тоже мало беспокоится по поводу AI, но совсем по другой причине: они думают, что создание сверхчеловечески сильного искусственного интеллекта настолько сложно технически, что никак не может произойти в ближайшие сотни лет, и беспокоиться об этом сейчас просто глупо. Я называю такую позицию техноскептицизмом, и ее предельно красноречиво сформулировал Эндрю Ын: “Бояться восстания роботов‑убийц – все равно что переживать по поводу перенаселения Марса”. Эндрю был тогда ведущим специалистом в Baidu, китайском аналоге Google, и он недавно повторил этот аргумент во время нашего разговора в Бостоне. Он также сказал мне, что предчувствует потенциальный вред, исходящий от разговоров об AI‑рисках, так как они могут замедлить развитие всех AI‑исследований. Подобные мысли высказывает и Родни Брукс, бывший профессор MIT[2], стоявший за созданием роботизированного пылесоса Румба и промышленного робота Бакстера. Мне представляется любопытным тот факт, что хотя цифро‑утописты и техноскептики сходятся во взглядах на исходящую от AI угрозу, они не соглашаются друг с другом почти ни в чем другом. Большинство цифро‑утопистов ожидают появления сильного AI (AGI) в период от двадцати до ста лет, что, по мнению техноскептиков, – ни на чем не основанные пустые фантазии, которые они, как и все предсказания технологической сингулярности, называют “бреднями гиков”. Когда я в декабре 2014 года встретил Родни Брукса на вечеринке, посвященной дню его рождения, он сказал мне, что на 100 % убежден, что ничего такого не может случиться при моей жизни. “Ты уверен, что имел в виду не 99 %?” – спросил я его потом в электронном письме. “Никаких 99 %. 100 %. Этого просто не случится, и все”.
Движение за дружественный AI
Впервые встретив Стюарта Рассела в парижском кафе в июне 2014 года, я подумал: “Вот настоящий британский джентльмен!”. Выражающийся ясно и обдуманно, с мягким красивым голосом, с авантюрным блеском в глазах, он показался мне современной инкарнацией Филеаса Фогга, любимого мною в детстве героя классического романа Жюля Верна Вокруг света за 80 дней. Хотя он один из самых известных среди ныне живущих исследователей искусственного интеллекта, соавтор одного из главных учебников на этот счет, его теплота и скромность позволили мне чувствовать себя легко во время беседы. Он рассказал, как прогресс в исследованиях искусственного интеллекта привел его к убеждению, что появление AGI человеческого уровня уже в этом столетии – вполне реальная возможность, и хотя он с надеждой смотрит на будущее, благополучный исход не гарантирован. Есть несколько ключевых вопросов, на которые мы должны ответить в первую очередь, и они так сложны, что исследовать их нужно начинать прямо сейчас, иначе ко времени, когда понадобится ответ, мы можем оказаться не готовы его дать.
Сегодня взгляды Стюарта в той или иной степени разделяет большинство, и немало групп по всему миру занимаются вопросами AI‑безопасности, как он и призывал. Но так было не всегда. В статье Washington Post 2015 год назван годом AI‑безопасности. А до тех пор рассуждения о рисках, связанных с разработками искусственного интеллекта, вызывали раздражение у большинства исследователей, относившихся к ним как к призывам современных луддитов воспрепятствовать прогрессу в этой области. Как мы увидим в главе 5, опасения, подобные высказанным Стюартом, были достаточно отчетливо артикулированы еще более полувека назад разработчиком первых компьютеров Аланом Тьюрингом и математиком Ирвингом Гудом, который работал с Тьюрингом над взломом германских шифров в годы Второй мировой войны. В прошлом десятилетии такие исследования велись лишь горсткой мыслителей, не занимавшихся созданием AI профессионально, среди них, например, Элиезер Юдковски, Майкл Вассар и Ник Бострём[3]. Их работа мало влияла на исследователей AI‑мейнстрима, которые были полностью поглощены своими ежедневными задачами по улучшению “умственных способностей” разрабатываемых ими систем и не задумывались о далеких последствиях своего возможного успеха. Среди них я знал и таких, кто испытывал определенные опасения, но не рисковал говорить о них публично, дабы не навлечь на себя обвинений коллег в алармизме и технофобии.
Я чувствовал, что такая поляризация мнений не навсегда и что исследовательское сообщество должно рано или поздно примкнуть к обсуждению вопроса, как сделать AI дружественным. К счастью, я был не одинок. Весной 2014 года я основал некоммерческую организацию под названием “Институт будущего жизни” (Future of Life Institute, или, сокращенно, FLI; http://futureoflife.org), в чем мне помогали моя жена Мейя, мой друг физик Энтони Агирре, аспирантка Гарварда Виктория Краковна и создатель Skype Яан Таллин. Наша цель проста: чтобы у жизни было будущее и чтобы оно было, насколько это возможно, прекрасно! В частности, мы понимали, что развитие технологий дает жизни небывалые возможности, она может теперь либо процветать, как никогда ранее, либо уничтожить себя, и мы бы предпочли первое.
Наша первая встреча состоялась у нас дома 15 марта 2014 года и приняла характер мозгового штурма. В ней участвовало около 30 студентов и профессоров MIT, а также несколько мыслителей, живущих по соседству с Бостоном. Мы все пришли к согласию в том, что, хотя необходимо уделять некоторое внимание биотехнологии, ядерному оружию и климатическим изменениям, наша главная цель – сделать вопрос AI‑безопасности центральным в данной исследовательской области. Мой коллега по MIT физик Фрэнк Вильчек, получивший Нобелевскую премию за то, что разобрался, как работают кварки, предложил нам для начала выступить с авторской колонкой в каком‑нибудь популярном СМИ, чтобы привлечь к проблеме внимание и усложнить жизнь тем, кто хотел бы ее проигнорировать. Я связался со Стюартом Расселом (с которым тогда еще не был знаком) и со Стивеном Хокингом, еще одним моим коллегой‑физиком, и они оба согласились присоединиться к нам с Фрэнком в качестве соавторов этой колонки. Что бы ни говорили об этом позже, но тогда New York Times отказалась публиковать нашу колонку, а за ней многие другие американские газеты, так что в итоге мы разместили ее в моем блоге на Huffington Post. Сама Арианна Хаффингтон, к моей радости, откликнулась письмом в электронной почте: “Я в восторге от поста! Мы поместим его #1!”, и это размещение нашей заметки в самой верхней позиции главной страницы вызвало лавину публикаций о AI‑безопасности, заняв первые полосы многих изданий до конца года, с участием Илона Маска, Билла Гейтса и других знаковых фигур современных технологий. Книга Ника Бострёма Superintelligence, вышедшая той же осенью, подлила масла в огонь и еще больше подогрела публичную дискуссию.
Следующим шагом нашей кампании за дружественный AI, проводимой под эгидой Института, стала организация большой конференции при участии всех ведущих специалистов по искусственному интеллекту с целью разобраться во всех недоразумениях, достичь принципиального согласия и составить конструктивный план на будущее. Мы хорошо понимали, что убедить столь блистательную публику собраться на конференцию, организуемую неизвестными им аутсайдерами, будет не просто, и поэтому старались изо всех сил: мы запретили доступ на нее любым СМИ, тщательно выбрали место и время – январь месяц и пуэрто‑риканский пляж, сделали бесплатным участие (нам позволила это щедрость Яана Таллина), мы придумали для нее наименее тревожное название, на какое только были способны: “Будущее AI: возможности и опасности”. Но самое главное – мы скооперировались со Стюартом Расселом и благодаря ему сумели пригласить в организационный комитет нескольких ведущих специалистов по искусственному интеллекту как из университетской среды, так и от бизнеса. В их числе был Демис Хассабис из лаборатории DeepMind, который как раз только что показал, что искусственный интеллект может обыграть человека даже в такую игру, как го. И чем больше я узнавал Демиса, тем больше понимал, что среди его амбициозных целей не только увеличение мощности искусственного интеллекта, но и достижение его дружественности.
Результатом стала невероятная встреча замечательных умов (см. рис. 1.3). К специалистам по искусственному интеллекту присоединились лучшие экономисты, юристы, лидеры технологии (включая Илона Маска) и иные мыслители (в том числе Вернор Виндж, придумавший термин “сингулярность”, вокруг которого все будет построено в главе 4). В конце концов все сложилось лучше, чем в наших самых смелых мечтах. Вероятно, все дело в удачном сочетании вина и солнца, а может быть, просто правильно было выбрано время: несмотря на полемическую повестку конференции, возник замечательный консенсус, изложенный в итоговом письме{1}[4], которое подписали более восьми тысяч человек, включая тех, без чьих имен не обойдется ни один справочник. Смысл письма заключался в том, что цель разработок искусственного интеллекта следует переопределить: создаваемый интеллект не должен быть неконтролируемым, он должен быть дружественным. В письме формулировался подробный список исследовательских задач, вокруг которых участники конференции соглашались концентрировать свою работу. Дружественный AI начинал превращаться в мейнстрим. Мы проследим за его прогрессом в этой книге.
В ходе конференции мы получили еще один урок: успех в создании искусственного интеллекта не просто будоражит мысль, он ставит серьезные вопросы, имеющие огромное моральное значение – от ответов на них зависит будущее всего живого, всей жизни. В прошлом моральная значимость принимаемых людьми решений могла быть очень велика, но она всегда оставалось ограниченной: человечество оправилось от самых жутких эпидемий, и даже величайшие империи в конце концов развалились. Прошлые поколения могли быть уверены, что наступит завтра и придут новые люди, пережившие обычные беды нашего мира: бедность, болезни, войны. И на конференции в Пуэрто‑Рико были такие, кто говорил, что сейчас настало другое время: впервые, говорили они, мы можем построить достаточно мощную технологию, которая способна навсегда избавить мир от этих бед – или от самого человечества. Мы можем создать общества, которые будут процветать, как никогда ранее, на Земле и, возможно, не только, а можем создать кафкианское, за всеми следящее государство, от которого уже никогда не удастся избавиться.
Хотя СМИ часто изображают дело так, словно Илон Маск на ножах с AI‑сообществом, на самом деле существует практически единодушное согласие по поводу необходимости исследований в области безопасности искусственного интеллекта. Здесь на фотографии 4 января 2015 года президент Ассоциации за развитие искусственного интеллекта Том Диттерих делится радостью со стоящим рядом Илоном Маском, который только что объявил о своем намерении финансировать новую программу исследований по AI‑безопасности. У них из‑за спин выглядывают сооснователи Института будущего жизни (FLI) Мейя Чита‑Тегмарк и Виктория Краковна.
Недоразумения
Я покидал Пуэрто‑Рико в убеждении, что начатый тут разговор о будущем AI следует продолжить, потому что это самый важный разговор нашего времени[5]. Причем этот разговор касается нашего общего будущего, и поэтому не должен вестись только в кругу AI‑экспертов. Именно поэтому я и написал эту книгу: я писал ее в надежде, дорогой читатель, что и вы присоединитесь к этому разговору! На какое будущее вы надеетесь? Надо ли нам развивать автономное летальное оружие? Какого рода автоматизации хотели бы вы у себя на работе? Какого образования вы бы хотели для своих детей? Предпочли бы вы, чтобы на смену старым профессиям пришли новые, или вам больше нравится общество бездельников, где каждый наслаждается досугом, а богатство создается машинами? Двигаясь дальше в том же направлении, находите ли вы благоприятной перспективу создания Жизни 3.0 и ее распространения по нашему космосу? Сможем ли мы управлять мыслящими машинами, или это они скорее начнут управлять нами? Заменят ли думающие машины нас, будем ли мы сосуществовать друг с другом или объединимся в некое единое целое? Что значит оставаться людьми в эпоху искусственного интеллекта? Какой ответ на этот вопрос вам представляется желательным, и как вы представляете себе возможность реализации этого ответа в нашей будущей жизни?
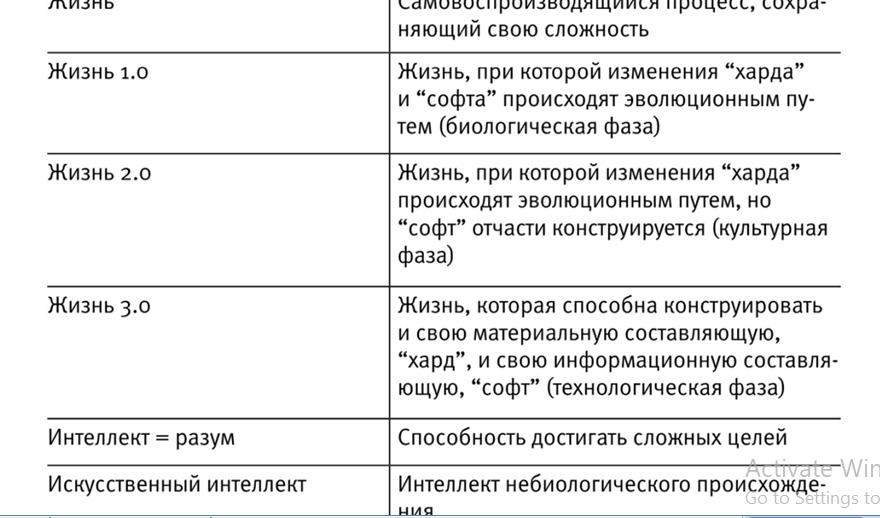
У таких важных и часто используемых понятий, как “жизнь”, “разум” и “сознание”, есть много общеупотребительных и конкурирующих определений, и недоразумения нередко возникают по вине людей, не отдающих себе отчет в том, что они используют одно и то же слово в двух разных значениях.
Хронологические мифы
Cколько времени понадобится, чтобы машинный интеллект мог принципиально превзойти человеческий разум? Самая большая ошибка здесь заключается в уверенности, что мы можем знать это с большой степенью точности.
Так, один популярный миф утверждает, что мы можем не сомневаться в появлении суперинтеллекта к концу этого столетия. В самом деле, история полна примеров чрезмерного оптимизма в отношении технологических достижений будущего. Где все эти давно обещанные нам термоядерные электростанции и летающие автомобили? С AI в прошлом тоже было связано немало чрезмерно завышенных ожиданий, в том числе этим грешили и некоторые основатели самой этой области: например, Джону Маккарти (автору термина “искусственный интеллект”), Марвину Мински, Натаниелю Рочестеру и Клоду Шеннону принадлежит следующий пассаж, содержащий оптимистический прогноз относительно того, что может быть проделано при помощи двух компьютеров каменного века за два месяца: “Наш проект заключается в том, чтобы 10 человек проводили на протяжении двух месяцев летом 1956 года исследование искусственного интеллекта в Дартмутском колледже … Будет сделана попытка научить машины использовать язык, формировать абстракции и общие понятия, решать некоторые типы задач, в настоящее время доступных только людям, и самосовершенствоваться. Мы полагаем, что в одном или нескольких из предложенных направлений может быть достигнут существенный прогресс, если тщательно отобранная группа ученых будет заниматься ими на протяжении лета”.

Типичные мифы об искусственном интеллекте.
С другой стороны, у нас есть и анти‑миф: мы можем не сомневаться в том, что суперинтеллект не появится до конца этого столетия. Исследователи предлагают широкий спектр оценок того, как далеко мы находимся от сверхчеловеческого AGI, но мы никак не можем с уверенностью утверждать, что вероятность получить его к концу века равна нулю, особенно если примем во внимание всю историю удручающе низкой точности предсказаний подобного рода техноскептиков. Вспомним, как Эрнест Резерфорд, по общему признанию величайший физик‑ядерщик своего времени, в 1913 году – всего лишь за 24 года до открытия Лео Сцилардом ядерных цепных реакций – называл возможность получения ядерной энергии “лунным светом”, или как в 1956 году королевский астроном Ричард Вули называл разговоры о полетах в космос “полной мутью”. Крайнюю форму этот миф принимает в рассуждениях об искусственном интеллекте, который никогда не сможет стать сверхчеловеческим, потому что это физически невозможно. Но физики знают, что мозг состоит из кварков и электронов, упорядоченных так, что они могут работать как мощный компьютер, и что нет такого физического закона, который мог бы помешать нам создать еще более разумный комок кварков.
Было проведено несколько крупных исследований на экспертных фокус‑группах среди специалистов по искусственному интеллекту, где им предлагалось оценить, сколько времени от текущего момента может пройти, пока вероятность создания искусственного интеллекта человеческого уровня достигнет 50 %, и все эти исследования оканчивались одним и тем же: мнения ведущих мировых исследователей по этому поводу расходятся, так что мы просто не знаем. Например, во время такого опроса на нашей конференции в Пуэрто‑Рико медианный ответ соответствовал 2055 году, но некоторые предсказывали сотни лет или даже больше.
Еще один имеющий отношение к тому же вопросу миф заключается в том, что люди, переживающие по поводу искусственного интеллекта, ждут его появления уже в ближайшие годы. На самом же деле подавляющее большинство из тех, чье мнение в данном вопросе значимо и кто действительно беспокоится о негативных последствиях создания AI, не ждут его раньше, чем через несколько десятилетий. Но они говорят: коль скоро у нас нет 100 % гарантий, что такое не может случиться уже в этом столетии, стоит начать вести исследования вопросов AI‑безопасности уже сейчас и быть готовыми к неожиданностям. Как мы увидим в этой книге, некоторые из вопросов безопасности настолько сложны, что на их решение могут уйти десятилетия, и есть смысл заняться ими сейчас, а не накануне той ночи, когда какие‑то попивающие “Рэд Булл” программисты решат запустить AGI человеческого уровня.
Мифы о природе рисков
Прочитав в Daily Mail заголовок “Стивен Хокинг предостерегает, что восстание роботов может оказаться катастрофическим для человечества”, я закрыл глаза{2}. Я уже потерял счет таким статьям. Обычно они сопровождаются картинкой со злобным роботом, волокущим какое‑нибудь оружие, и готовят нас к тому, что когда‑нибудь роботы обретут сознание, преисполнятся злобой и поднимут восстание, которого нам следует опасаться. В определенном смысле такие статьи производят на меня сокрушительное впечатление, потому что в сжатой форме предлагают как раз тот самый сценарий, который никак не пугает моих коллег по исследованию AI. Этот сценарий содержит в себе сразу три глубочайших заблуждения, относящихся к трем разным понятиям: наше беспокойство должны вызывать сознание, злобность и вообще роботы.
Когда вы едете на машине по дороге, ваше восприятие световой и звуковой гамм субъективно. А есть ли субъективное восприятие у беспилотного автомобиля? Чувствует ли он себя настоящим беспилотником или просто катится по дороге, как неразумный зомби, лишенный всякого субъективного восприятия? Хотя эта загадка – что значит быть сознающим – сама по себе интересна и мы посвятим ей 8‑ю главу, она не имеет никакого отношения к теме AI‑рисков. Если на вас налетит беспилотный автомобиль, вам будет безразлично, осознавал ли он себя в этот момент. Точно так же нас беспокоит не то, что почувствует сверхчеловеческий разум, а что он будет делать.
Страх, что машины окажутся злонамеренными, – еще одна расхожая бессмыслица. Наше опасение вызывают их компетенции, а не злая воля. По определению сверхразумный AI исключительно эффективен в достижении своих целей, каковы бы они ни были, и нам важно, чтобы эти цели не противоречили нашим. Вряд ли вы относитесь к тем ненавистникам муравьев, кто топчет их по злобе, но если вы руководите проектом по постройке “зеленой” гидроэлектростанции и на предназначенном под затопление участке вдруг случайно окажется муравейник, то муравьям в нем не поздоровится. Движение за дружественный AI ставит перед собой задачу сделать так, чтобы люди никогда не оказывались в положении этих муравьев.
Недоразумение по поводу сознательных машин тесно связано с представлением, будто у машин не может быть целей. У машины, очевидно, могут быть цели в том смысле, что она может проявлять целеустремленное поведение: поведение ракеты, движущейся на источник тепла, наиболее естественно объяснить целью поразить самолет противника. Если вы испытываете беспокойство по поводу того, что цель машины каким‑то образом расходится с вашими собственными целями, вам безразлично, до какой степени она себя осознает и какими намерениями движима. Когда вы увидите у себя на хвосте самонаводящуюся ракету, вы не станете успокаивать себя мыслью: “У машины не может быть целей!”.
Я с симпатией отношусь и к Родни Бруксу, и к другим пионерам робототехники, которые были возмущены тем, как сеющие ужас таблоиды несправедливо демонизируют их, когда их журналисты, зациклившиеся на роботах, начинают украшать свои статьи злобными металлическими монстрами с красными светящимися глазами. На самом же деле в центре внимания движения за дружественный AI вовсе не роботы, а сам искусственный интеллект, точнее говоря, – разум с целями, не совместимыми с нашими. Для того чтобы нарушить наш покой, такому не совместимому с нашим разуму вовсе не нужно тело робота, ему достаточно доступа в интернет – в главе 4 мы покажем, как, воспользовавшись этим, он купит и перепродаст всех на финансовых рынках, затмит изобретательностью любых изобретателей, покорит своей демагогией больше обывателей, чем любой человеческий политический лидер, и придумает оружие, принципов действия которого мы даже не будем понимать. Даже если бы создание роботов было физически невозможно, сверхразумный и сверхбогатый искусственный интеллект легко бы подкупал мириады человеческих существ и манипулировал бы ими, неумышленно вовлекая их в свои изощренные торговые операции, как это происходит в фантастическом романе Уильяма Гибсона Neuromancer.
Недоразумение с роботами напрямую связано с мифом, будто машины не могут управлять людьми. Разум – путь к управлению: человек может командовать тигром не потому, что сильнее, а потому, что умнее. Если мы уступим свое положение самых умных на планете, мы можем потерять и контроль над собой.
На рис. 1.5 все эти общие недоразумения собраны воедино, так чтобы мы могли покончить с ними раз и навсегда и сосредоточить наши дискуссии с друзьями и коллегами вокруг настоящих противоречий, в которых, как мы сейчас убедимся, нет недостатка.
Дорога вперед
Какие именно вопросы относительно искусственного интеллекта представляют интерес, зависит от того, насколько он развит, и от того, по какому направлению стало развиваться наше будущее.
Уже сейчас перед нами стоит вопрос о начале своего рода гонки вооружений, использующих AI‑технологии, а также целый ряд вопросов о том, как сделать завтрашний AI надежным и работающим без “глюков”. Если позитивное влияние AI‑технологий на экономику будет расти, нам придется решать, как преобразовывать законодательную систему и на какую карьеру ориентировать наших детей, чтобы они не оказывались вовлеченными в ту профессиональную деятельность, которой грозит скорая автоматизация. Мы рассмотрим все эти насущные уже в краткосрочной перспективе вопросы в главе 3.
Если AI в своем развитии достигнет человеческого уровня, нам придется спросить себя: а как сделать его дружественным? можем ли мы обеспечить себе с его помощью праздную жизнь? хотим ли мы этого? Отсюда также возникает вопрос о возможности AI за счет взрывного развития или постепенного, но неуклонного роста достичь уровня, значительно превосходящего человеческий.
Кто стоит во главе – человек, AI или киборг? Хорошо ли с людьми обращаются? Если на смену людям приходят какие‑то иные сущности, должны ли мы рассматривать пришедших как захватчиков или как потомков, достойных своих предков? Мне очень интересно, какой из предложенных в главе 5 сценариев кажется наиболее предпочтительным лично вам! Я создал вебсайт http://AgeOfAi.org, для того чтобы вы могли поделиться своими мыслями и присоединиться к разговору.
[1] В англоязычном мире имя этого человека принято транслитерировать иначе: “Моравек”, но мы будем придерживаться исходного, чешского варианта. – Прим. перев.
[2] Массачусетский технологический институт в Кембридже (штат Массачусетс). – Прим. перев.
[3] Фамилию этого шведского ученого, живущего и работающего в Англии, часто транскрибируют без учета умляута над вторым “о” – “Бостром”. Более точной и более традиционной была бы транскрипция “Бустрём”, но мы решили остановиться на компромиссном варианте “Бострём”. – Прим. перев.
[5] Необходимость здесь двоякая: и по силе воздействия, и по насущности проблемы. В сравнении с климатическими изменениями, катастрофические последствия которых ожидаются в период от пятидесяти до двухсот лет, считая от настоящего момента, AI, по оценкам некоторых экспертов, может привести к столь же пагубным последствиям в течение ближайших десятилетий – при этом он же может создать технологию смягчения климатических изменений. А в сравнении с войнами, терроризмом, безработицей, нищетой, миграцией и нарушениями прав человека – общий эффект от создания и внедрения AI может значительно превысить совокупные последствия всего перечисленного (мы как раз и собираемся разобраться ниже, каким именно образом AI может здесь перевесить), причем как усугубляя, так и компенсируя его.






Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария:
Рейтинг комментария: